






服务器高可用恢复演练方案
概述
演练目的
由于历史原因,A 系统存在部分项目使用 CVM 作为运行环境。尽管腾讯云方承诺单实例服务的可用性达到 99.975%,但遇到 Linux 内核故障、CPU 或内存的使用率过高等问题,仍然会导致系统不可用。为避免业务中断,使用腾讯云 CLB 作为负载均衡,管理和分流至少 3 台以上的 CVM 实例,实现高可用。
目标要求
通过混沌演练故障注入,验证 A 系统当前的部署架构具备自愈能力,对业务的影响在可接受范围,满足金融行业IT系统容灾标准,灾难恢复能力达到国家标准等级 4 级以上,即 RPO 不超过 4 小时,RTO 不超过 12 小时。
名词解释
| 名词 | 解释 |
|---|---|
| RPO | 恢复点目标(Recovery Point Object,简称 RPO)。指灾难发生后,容灾系统进行数据恢复,恢复得来的数据所对应的时间点。 |
| RTO | 恢复时间目标(Recovery Time Object,简称 RTO)。指灾难发生后,从 IT系统宕机导致业务停顿之刻开始,到 IT 系统恢复至可以支持各部门运作,业务恢复运营之间的时间段。 |
| CVM | 云服务器(Cloud Virtual Machine,CVM)是腾讯云提供的可扩展的计算服务。可以避免使用传统服务器时需要预估资源用量及前期投入的问题,并在短时间内快速启动任意数量的云服务器并及时部署应用程序。具体可查阅文档。 |
| CLB | 负载均衡(Cloud Load Balancer,CLB)提供安全快捷的流量分发服务,访问流量经由 CLB 可以自动分配到云中的多台后端服务器上,扩展系统的服务能力并消除单点故障。负载均衡支持亿级连接和千万级并发,可轻松应对大流量访问,满足业务需求。具体可查阅文档。 |
| CFG | 混沌演练(Chaotic Fault Generator)提供高效便捷、安全可靠的故障演习服务,除可视化故障注入服务外,还提供行业经验模板,监控护栏等核心功能,帮助用户及时发现业务容灾隐患、验证高可用预案的有效性,从而提高系统的可用性和韧性。具体可查阅文档。 |
方案
系统分析
本次演练的对象为 A 系统的生产环境,访问地址为 https://www.XXX.com。
该系统使用负载均衡 CLB 提供公网访问入口,CLB 对上游的存活检测规则,响应超时为 2 秒,检查间隔为 5 秒,不健康阈值为 3 次,健康阈值为 3 次。当某个 CVM 实例发生故障时,超过 21 秒后判断该实例不健康,不再分发流量。
CLB 的上游绑定 5 个机器节点,各节点的规格统一为 8 核 16 GB,如下。
- gray 灰度环境:内网 IP 为 172.28.0.1(这个有前端依赖,不适合做故障注入)
- prd1 生产环境:内网 IP 为 172.28.0.2
- prd2 生产环境:内网 IP 为 172.28.0.3
- prd3 生产环境:内网 IP 为 172.28.0.4
- prd4 生产环境:内网 IP 为 172.28.0.5
因各节点规格一致,计划使用 prd1 生产环境作为测试对象。
实施时间
选定 2023 年 6 月 25 日(非交易日,用户访问量少)
人员分工
由演练领导组、演练实施组、演练指挥组和业务验证组共同参与,具体人员如下。
| 灾备演练组 | 人员 | 岗位 | 职责 |
|---|---|---|---|
| 演练领导组 | 小A | 技术总监 | 负责容灾方案的审核和决策 |
| 演练指挥组 | 小B | 云原生专家 | 负责制定容灾方案和发起 |
| 演练实施组 | 小C | 平台工程师 | 负责实施应用平台的容灾恢复 |
| 演练实施组 | 小D | 运维工程师 | 负责实施基础设施的容灾恢复 |
| 业务验证组 | 小E | 研发负责人 | 负责业务监控和系统可靠性验证 |
| 业务验证组 | 小F | 研发工程师 | 负责业务测试和容灾恢复前后的数据比对验证 |
整体流程
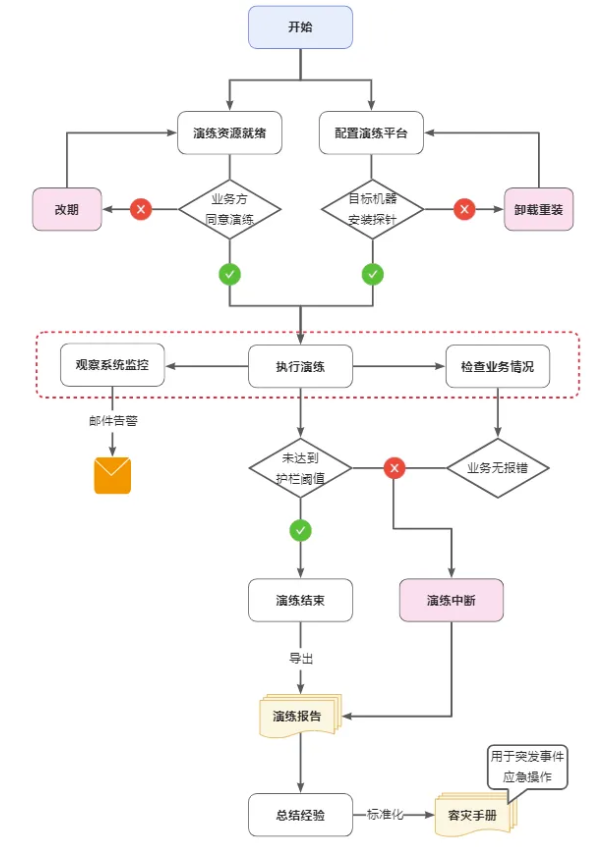
准备工作
本次演练基于腾讯云混沌演练平台完成故障注入和灾难恢复工作,在正式执行容灾演练前,需要预先创建好相关任务、动作库、监控护栏、演练计划等配置。
创建演练任务
演练名称设置为 “CVM 故障注入恢复演练”。
配置动作库
分别创建任务,依次为:Linux 内核故障、CPU 利用率100%、内存利用率100% 、主机异常重启。

设置监控护栏
防止演练过程中出现一些不可预估的影响,使用护栏策略触发告警,中断演练执行。

保存到经验库
将已配置的流程保存起来,以便后续演练复用,经验名称为 “CVM 故障注入案例”。
新建演练计划
设置演练起止时间,并选择创建好的经验库。
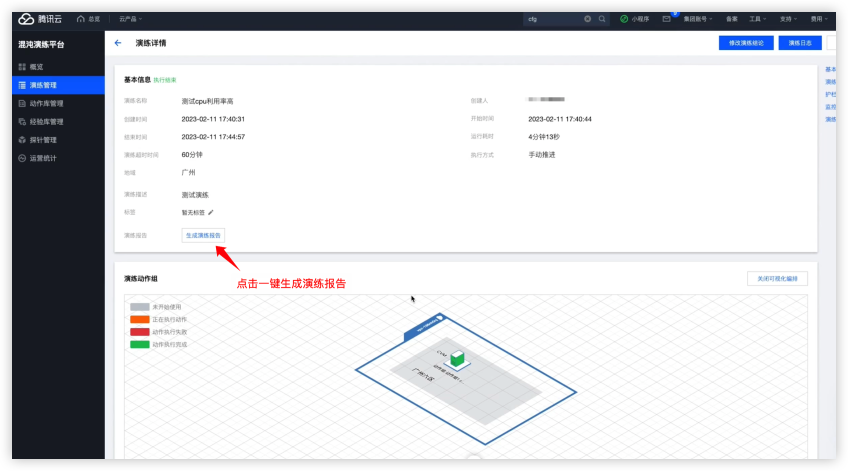
演练事后总结
演练结束后,点击按钮生成演练报告。
演练内容
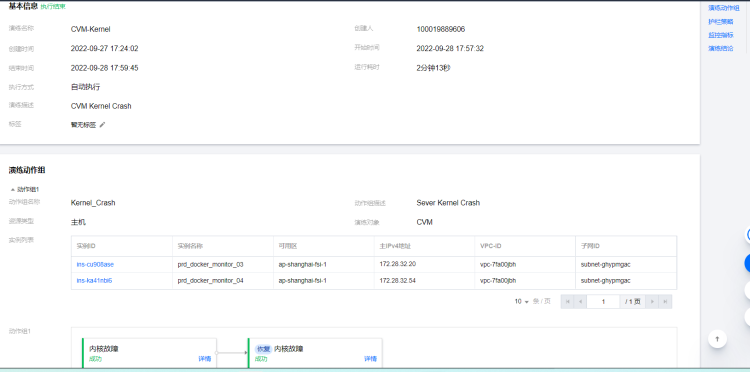
Linux内核故障恢复演练
故障模拟:prd1 服务器节点发生内核故障
执行步骤:
- 针对 prd1 环境执行
Linux内核故障注入,从控制台面板查看故障是否注入完成。 - 登录 CVM 执行
Top命令,查看是否产生一个chaos_burnkernel进程。 - 故障注入 1 分钟,不做 CLB 流量切换,观察系统和日志的表现。
- 再次执行故障注入 1 分钟,当收到系统告警,人工介入 CLB 流量切换,观察系统和日志的表现。
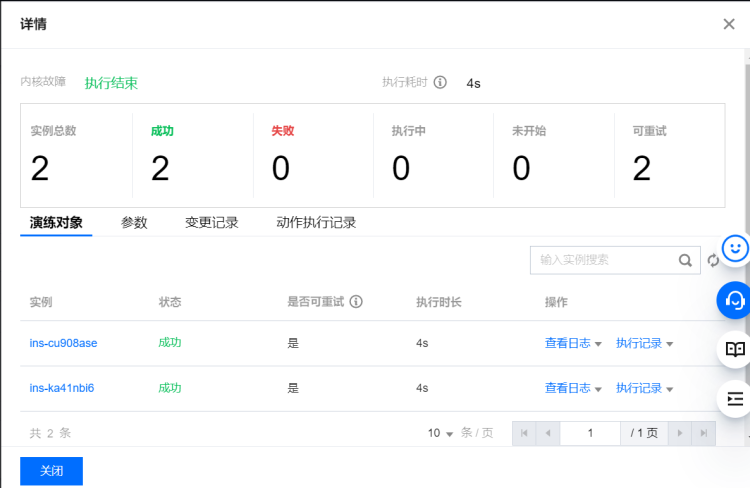
期望结果:
- 首次故障注入,不做 CLB 切换,CLB 在 21 秒后检测到目标 CVM 不可用,业务请求随后恢复正常。
- 再次故障注入,系统自动告警,手动切换 CLB 到正常节点,业务请求快速恢复正常,故障恢复时长 RTO 在可接受范围内。
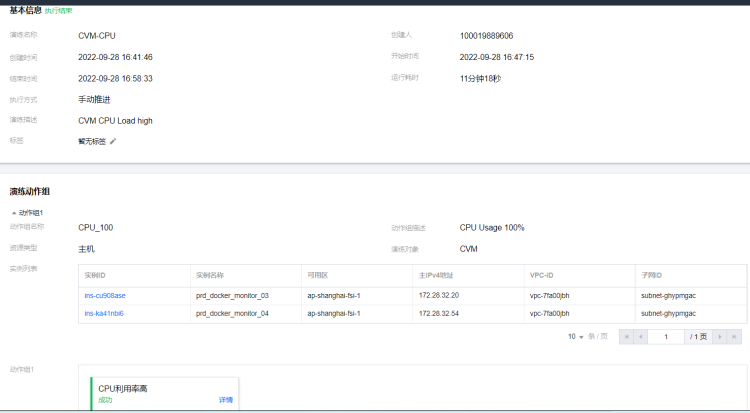
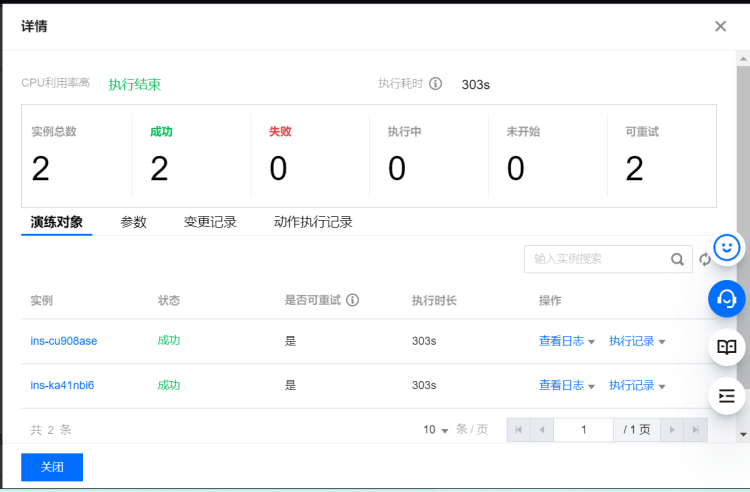
CPU使用100%恢复演练
故障模拟:prd1 服务器节点的 CPU 利用率达到 100%
执行步骤:
- 针对 prd1 环境执行
CPU使用率100%注入,从控制台面板查看故障是否注入完成。 - 登录 CVM 执行
Top命令,查看是否产生一个chaos_burnkernel进程。 - 故障注入 1 分钟,不做 CLB 流量切换,观察系统和日志的表现。
- 再次执行故障注入 1 分钟,当收到系统告警,人工介入 CLB 流量切换,观察系统和日志的表现。
期望结果:
- 首次故障注入,不做 CLB 切换,CLB 在 21 秒后检测到目标 CVM 不可用,业务请求随后恢复正常。
- 再次故障注入,系统自动告警,手动切换 CLB 到正常节点,业务请求快速恢复正常,故障恢复时长 RTO 在可接受范围内。
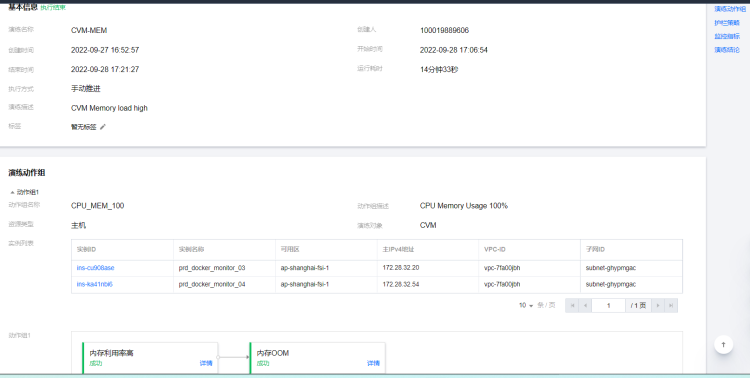
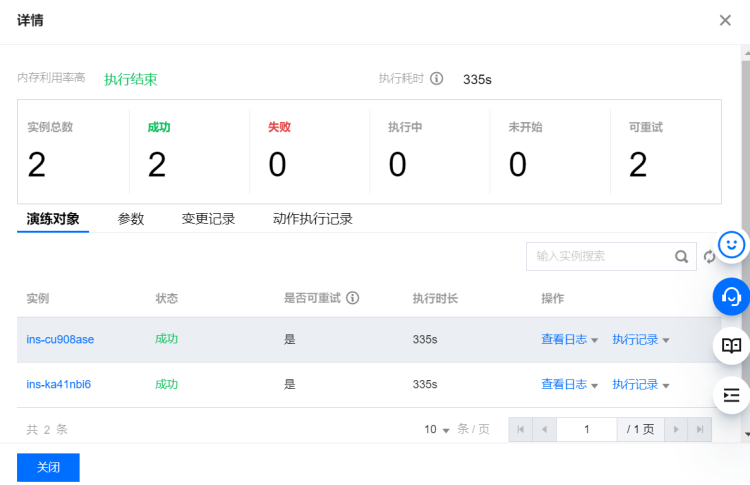
内存使用100%恢复演练
故障模拟:prd1 服务器节点的内存利用率达到 100%
执行步骤:
- 针对 prd1 环境执行
内存使用率100%注入,从控制台面板查看故障是否注入完成。 - 登录 CVM 执行
Top命令,查看是否产生一个chaos_burnmem进程。 - 故障注入 1 分钟,不做 CLB 流量切换,观察系统和日志的表现。
- 再次执行故障注入 1 分钟,当收到系统告警,人工介入 CLB 流量切换,观察系统和日志的表现。
期望结果:
- 首次故障注入,不做 CLB 切换,CLB 在 21 秒后检测到目标 CVM 不可用,业务请求随后恢复正常。
- 再次故障注入,系统自动告警,手动切换 CLB 到正常节点,业务请求快速恢复正常,故障恢复时长 RTO 在可接受范围内。
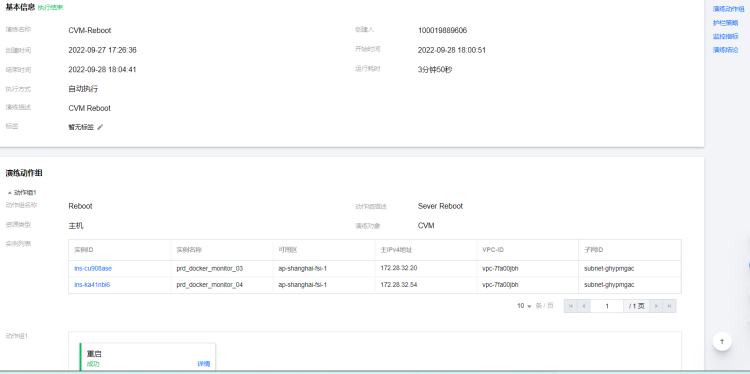
机器故障重启恢复演练
故障模拟:prd1 服务器节点宕机重启
执行步骤:
- 针对 prd1 环境执行
机器故障重启注入,从控制台面板查看故障是否注入完成。 - 登录 CVM 执行
Top命令,查看是否产生一个chaos_burnreboot进程。 - 故障注入 1 分钟,不做 CLB 流量切换,观察系统和日志的表现。
- 再次执行故障注入 1 分钟,当收到系统告警,人工介入 CLB 流量切换,观察系统和日志的表现。
期望结果:
- 首次故障注入,不做 CLB 切换,CLB 在 21 秒后检测到目标 CVM 不可用,业务请求随后恢复正常。
- 再次故障注入,系统自动告警,手动切换 CLB 到正常节点,业务请求快速恢复正常,故障恢复时长 RTO 在可接受范围内。
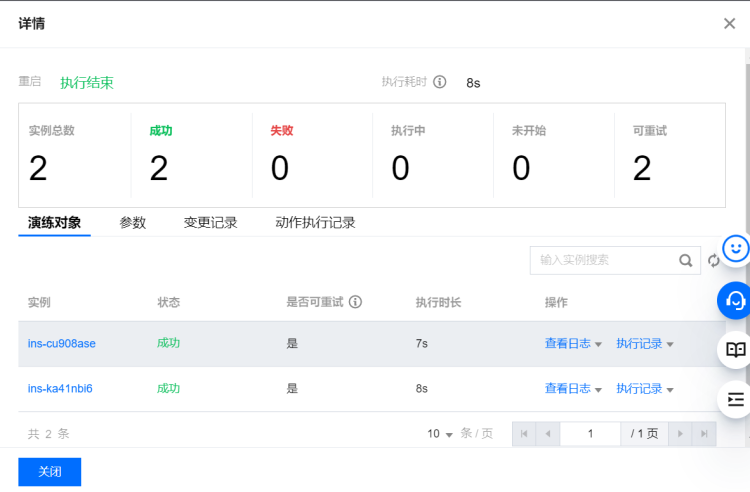
现场还原
在故障注入期间,会额外产生 chaos_burncpu、chaos_burnmem 等进程,在混沌演练平台执行销毁探针可能会不成功,需要人工检查这些进程是否存在,按需销毁这些驻留进程。
数据核对
由于演练过程中并不产生数据写入,因此,无须进行数据核对。
 微信
微信- 支付宝



